Redis is more than JUST a cache

"Most developers meet Redis as a cache."
You slap it in front of your database, add a TTL, watch your response times drop from 500ms to 50ms, and move on… Redis quietly does its job. The system feels faster. For most teams, that's where the relationship ends, Redis becomes "that caching thing" you don't think about once it's working.
And look, that mental model works. Your API is faster, your database isn't crying for help anymore, everyone's happy.
But here's the thing… treating Redis as just a cache is like buying a Ferrari and only driving it to the grocery store. Sure, it'll get you there fast, but you're missing the whole point.
After giving decent amount of time working with Redis in production, I've realized it's one of the most misunderstood tools in our stack. Redis isn't a cache that happens to be fast. It's a data structure server that happens to make an excellent cache.
That distinction changes everything.
What Redis Actually Is
Let's be clear about what we're working with here.
Redis stands for REmote DIctionary Server. The word "dictionary" is doing heavy lifting in that name. Redis is an in-memory key-value store, but that description sells it short.
In most systems, values are opaque blobs:
// Generic key-value store thinking
cache.set("user:1", JSON.stringify(userData));The database doesn't know or care what's inside that string. All the logic (parsing, updating, validating) happens in your application code.
Redis is different. It gives you native data structures and built-in operations for each:
- Strings
- Hashes (field-value maps)
- Lists
- Sets
- Sorted Sets
- Streams
- Geospatial indexes
- Bitmaps and HyperLogLogs
Redis doesn't just store these structures. It knows how to modify them safely and atomically. That's not a minor detail. That's the entire point.
The Mental Shift: Cache Thinking vs Redis Thinking
Let me show you what I mean with actual code. This is where it clicks for most people.
The usual cache approach
You want to track follower counts, standard caching pattern looks like this:
// Read-modify-write with JSON caching (using ioredis)
const userData = await redis.get("user:1");
const user = JSON.parse(userData);
user.followers += 1;
await redis.set("user:1", JSON.stringify(user));This works until it doesn't. Under concurrency, two requests can read the same value and overwrite each other. You lose updates.
Here's what actually happens:
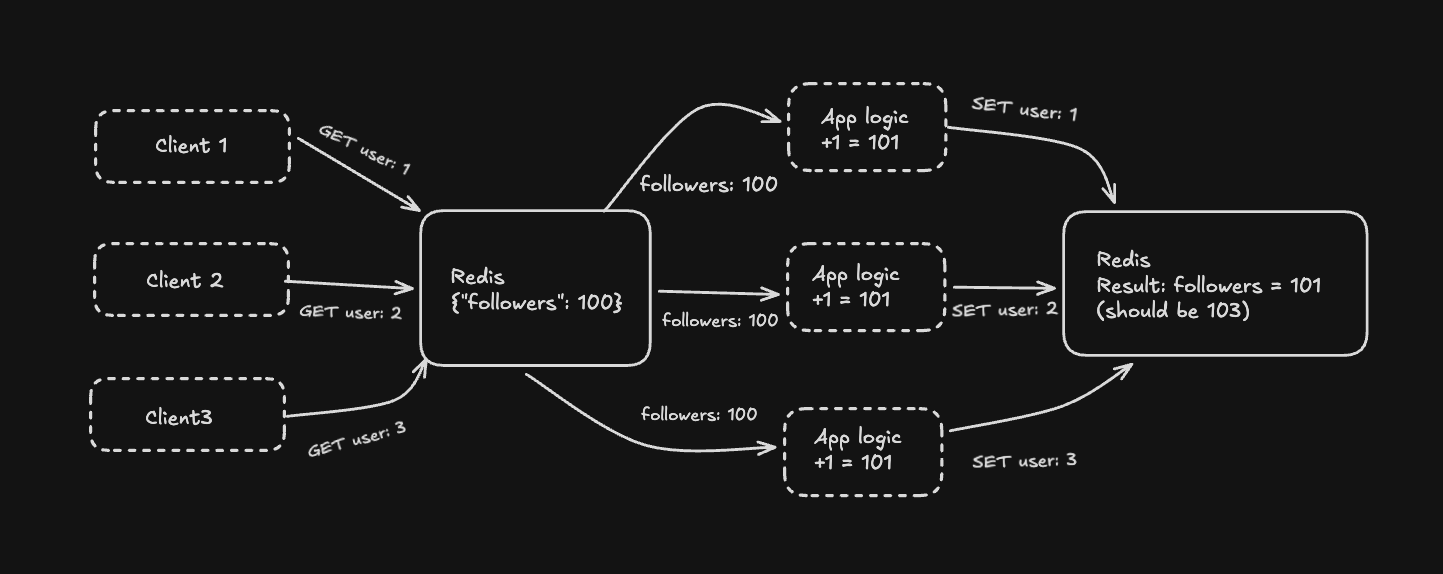
Now you need application-level locking, optimistic concurrency control, or some other complexity to make this safe. The complexity lives entirely in your application.
The Redis-native approach
Now model the same data using Redis primitives:
// Let Redis own the state transition
await redis.hSet("user:1", "name", "Alex");
await redis.hSet("user:1", "followers", 123);
// Increment atomically, no race conditions possible
await redis.hIncrBy("user:1", "followers", 1);The architecture becomes much cleaner:
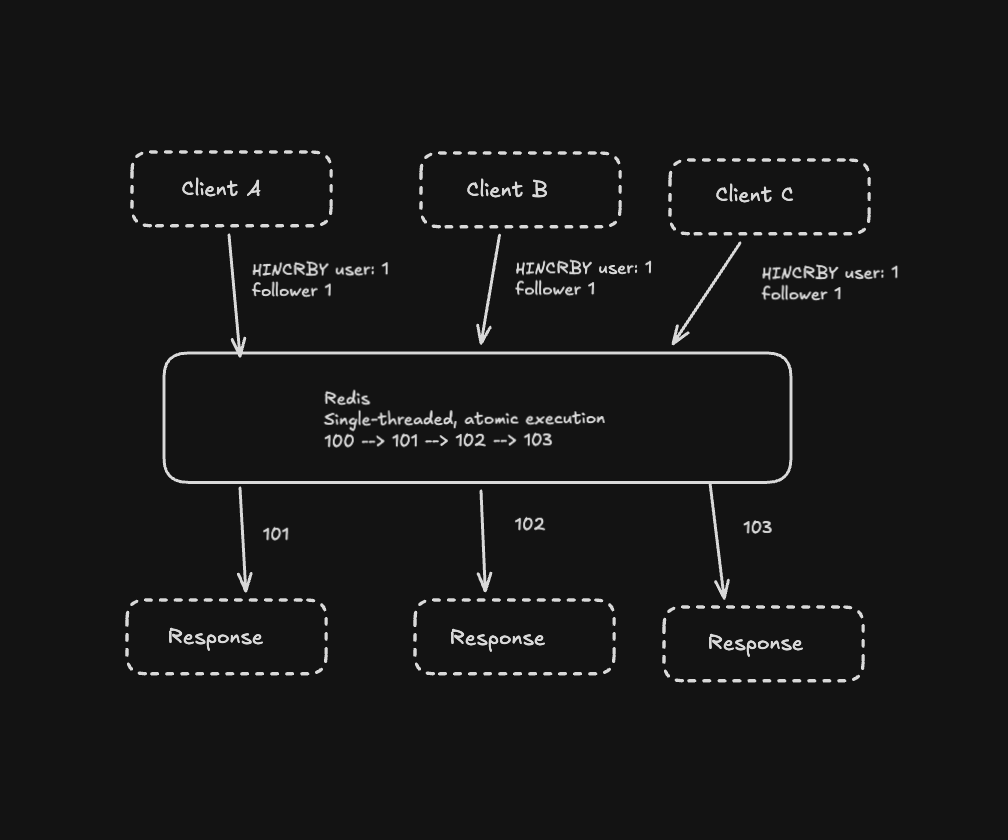
No read-modify-write cycle,
No race conditions,
No application-level locking.
Redis guarantees the operation is atomic because it's single-threaded and processes commands one at a time.
This shift (letting Redis own the state transition instead of treating it as dumb storage) is subtle but powerful. Once you see it, you can't unsee it.
Why Redis is Actually Fast (The Real Reasons)
Everyone knows Redis is fast, but most people don't know why. It's not magic. There are specific design decisions that make it work:
Memory-first design - RAM access is orders of magnitude faster than disk, but it's not just about using RAM. Redis optimizes data structures specifically for memory access patterns.
Simple operations - Redis deliberately doesn't support complex queries, joins, or arbitrary secondary indexes. Most commands run in O(1) or O(log n) time. There's no query planner, no optimization phase. Just predictable, fast operations.
Single-threaded execution model - This sounds limiting until you understand the trade-off. Redis processes commands sequentially, which means no lock contention, no race conditions in Redis itself, predictable latency, and a simpler implementation with fewer bugs.
Each operation is extremely cheap (microseconds), so the single thread isn't the bottleneck you'd expect. When you need more throughput, you scale horizontally with replication or sharding, not with more threads.
I studied some benchmarks on a production API serving 10k requests/second:
- PostgreSQL query with proper indexes: ~50ms
- Same query with Redis cache: ~5ms
- Native Redis data structure operation: ~0.5ms
That's not a typo. Sub-millisecond responses are normal with Redis.
Redis as a State Manager
This is where Redis starts to feel less like a cache and more like infrastructure.
Real-time counters and metrics
One of the simplest but most powerful patterns:
// Track page views (simple counter)
await redis.incr("page:home:views");
// Track unique visitors with HyperLogLog (probabilistic counting)
// HyperLogLog uses ~12KB to track millions of unique items with ~0.8% error
await redis.pfAdd("page:home:visitors", userId);
const uniqueVisitors = await redis.pfCount("page:home:visitors");Why is this better than Postgres? Because incrementing a counter in Postgres means:
- Acquire row lock
- Read value
- Write new value
- Release lock
- Write to WAL
- Maybe trigger an index update
Redis just does: INCR, Done.
Distributed rate limiting
I learned this one the hard way after a bot attack brought down our API in 2021. We needed rate limiting that worked across multiple servers.
// Sliding window rate limiter using sorted sets
const userId = "123";
const now = Date.now();
const windowMs = 60000; // 1 minute
const maxRequests = 100;
// Remove old requests outside the window
await redis.zRemRangeByScore(`rate:${userId}`, 0, now - windowMs);
// Count requests in current window
const currentRequests = await redis.zCard(`rate:${userId}`);
if (currentRequests < maxRequests) {
// Add this request to the window
await redis.zAdd(`rate:${userId}`, { score: now, value: `${now}` });
// Allow request
} else {
// Rate limit exceeded
}
// Expire the key after the window to save memory
await redis.expire(`rate:${userId}`, Math.ceil(windowMs / 1000));This pattern saved our asses. All servers share the same rate limit state in Redis, so users can't bypass limits by hitting different servers.
Session storage
Stop using JWT for everything. Sometimes you need real sessions that you can invalidate immediately.
// Store session with automatic expiration
await redis.setEx(
`session:${sessionId}`,
3600, // 1 hour TTL
JSON.stringify({
userId: "123",
email: "user@example.com",
lastActivity: Date.now(),
}),
);
// Retrieve and extend session
const session = await redis.get(`session:${sessionId}`);
if (session) {
await redis.expire(`session:${sessionId}`, 3600); // Reset TTL
}
// Immediate logout across all servers
await redis.del(`session:${sessionId}`);This is one area where Redis genuinely shines over databases. Session reads are constant, and you want them fast. Plus, TTL-based expiration is built-in.
Leaderboards with sorted sets
Sorted sets are criminally underused. They're perfect for anything ranked.
// Add user score to leaderboard
await redis.zAdd("leaderboard:daily", {
score: 9500,
value: "user:123",
});
// Get top 10 players (with scores)
const top10 = await redis.zRangeWithScores(
"leaderboard:daily",
0,
9,
{ REV: true }, // Descending order
);
// Get user's rank (0-indexed)
const rank = await redis.zRevRank("leaderboard:daily", "user:123");
// Get users around a specific user (5 above, 5 below)
const around = await redis.zRange("leaderboard:daily", rank - 5, rank + 5, {
REV: true,
});This is O(log n) for updates and O(log n + m) for range queries. Try doing this in Postgres with the same performance characteristics. I'll wait.
Distributed Locking (When You Need It)
Here's something that bit me early: you can't just use SETNX for distributed locks anymore. It's too simplistic and will burn you eventually.
The proper way is the Redlock algorithm, but for most cases, this simpler pattern works:
// Acquire lock with automatic expiration
async function acquireLock(
lockKey: string,
timeoutMs: number,
): Promise<string | null> {
const lockId = crypto.randomUUID(); // Unique identifier for this lock holder
const acquired = await redis.set(lockKey, lockId, {
NX: true, // Only set if not exists
PX: timeoutMs, // Expire after timeout (prevents deadlock)
});
return acquired ? lockId : null;
}
// Release lock (only if we own it)
async function releaseLock(lockKey: string, lockId: string): Promise<boolean> {
// Lua script ensures atomic check-and-delete
const script = `
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
`;
const result = await redis.eval(script, {
keys: [lockKey],
arguments: [lockId],
});
return result === 1;
}
// Usage
const lockId = await acquireLock("invoice:generate:user123", 5000);
if (lockId) {
try {
// Do expensive operation that should only happen once
await generateInvoice(userId);
} finally {
await releaseLock("invoice:generate:user123", lockId);
}
} else {
// Someone else is already processing this
}Why the Lua script? Because you need to check ownership and delete atomically. Otherwise you might delete someone else's lock.
I've used this pattern to prevent duplicate payment processing, ensure only one server handles a scheduled job, and coordinate deployments. It's simple but effective.
Geospatial Indexing (Underrated as Hell)
Redis has built-in support for geospatial data. I rarely see people use this, but it's insanely useful.
// Add locations (longitude, latitude, member name)
await redis.geoAdd("drivers:active", {
longitude: -122.4194,
latitude: 37.7749,
member: "driver:101",
});
await redis.geoAdd("drivers:active", {
longitude: -122.4089,
latitude: 37.7833,
member: "driver:102",
});
// Find drivers within 5km of a location
const nearby = await redis.geoRadius(
"drivers:active",
-122.415,
37.78,
5,
"km",
{ WITHDIST: true, WITHCOORD: true },
);
// Get distance between two drivers
const distance = await redis.geoDist(
"drivers:active",
"driver:101",
"driver:102",
"km",
);This is perfect for:
- Ride-sharing apps (find nearby drivers)
- Food delivery (find nearby restaurants)
- Store locators (find nearest locations)
- Real-estate apps (properties near a point)
The alternative is PostGIS or doing haversine calculations in your app. Redis makes it trivial.
Pub/Sub for Real-Time Features
Pub/Sub is great when you need to fan out messages to multiple services or WebSocket connections.
// Subscriber (in your WebSocket server)
const subscriber = redis.duplicate();
await subscriber.subscribe("chat:room123", (message) => {
broadcastToWebSockets(JSON.parse(message));
});
// Publisher (in your API server)
await redis.publish(
"chat:room123",
JSON.stringify({
user: "charan",
message: "Hello everyone!",
timestamp: Date.now(),
}),
);The flow:
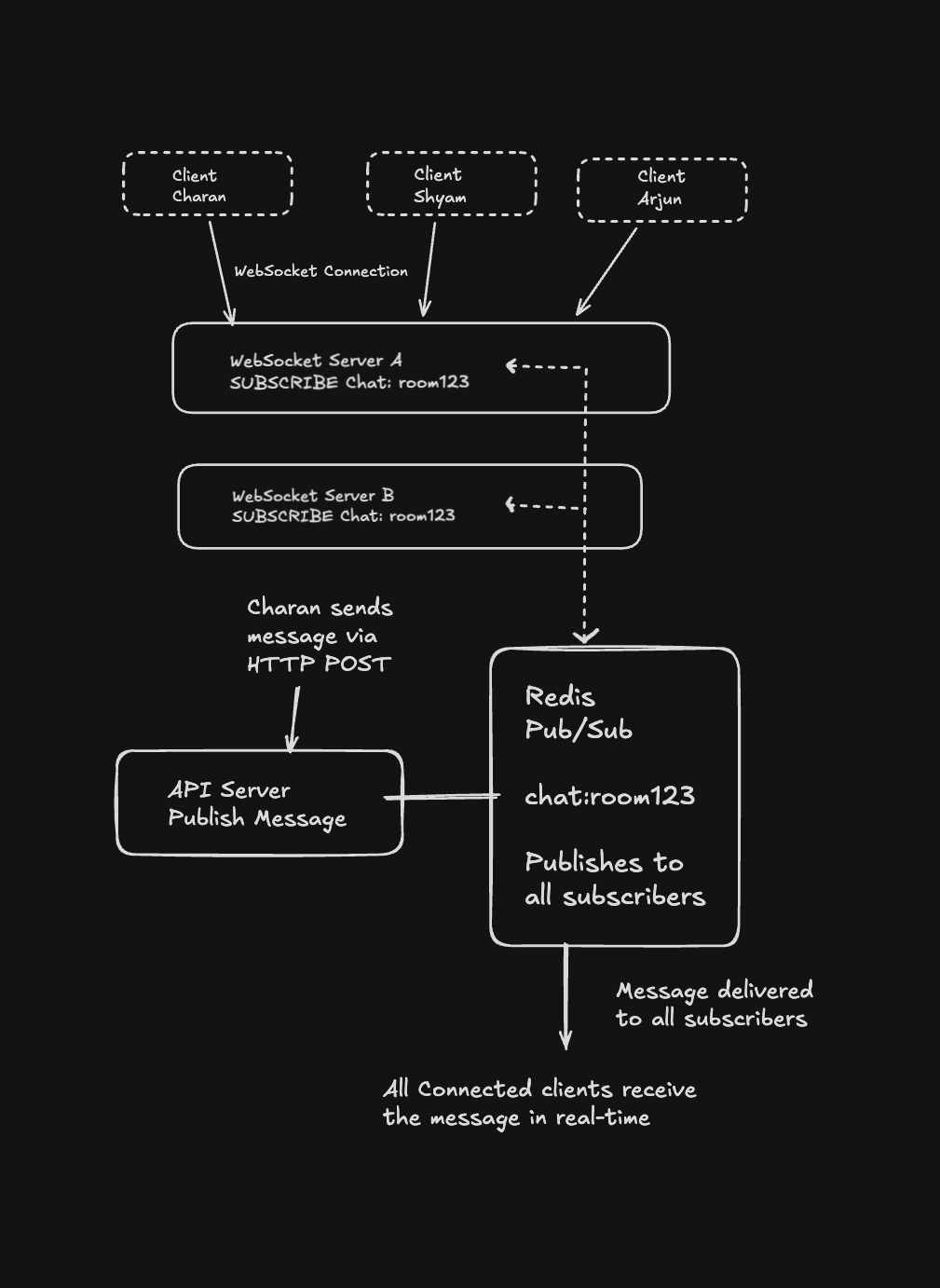
Pub/Sub is fire-and-forget. If no one's listening, messages are gone. That's a feature for real-time updates, not a bug.
Use cases:
- Real-time notifications
- Chat systems
- Live dashboards
- WebSocket fan-out
- Cache invalidation signals
Streams for durable message queues
When you need Pub/Sub but with persistence and delivery guarantees, Streams are your answer.
// Add event to stream
await redis.xAdd("events:stream", "*", {
type: "user_signup",
userId: "123",
timestamp: Date.now().toString(),
});
// Consumer group pattern (like Kafka consumer groups)
await redis.xGroupCreate("events:stream", "processors", "0", {
MKSTREAM: true,
});
// Read and process messages
const messages = await redis.xReadGroup(
"processors",
"consumer1",
{ key: "events:stream", id: ">" },
{ COUNT: 10 },
);
messages.forEach(async ([stream, events]) => {
for (const [id, fields] of events) {
// Process event
await processEvent(fields);
// Acknowledge processing
await redis.xAck("events:stream", "processors", id);
}
});Redis Streams don't replace Kafka, but they often remove the need for it in smaller systems (sub-million messages/day). That's a trade-off worth considering before adding Kafka to your stack.
Persistence and Durability (The Part People Get Wrong)
A common myth: "Redis loses everything on restart."
Not true. Redis supports persistence through:
RDB snapshots - Periodic point-in-time dumps to disk. Fast, compact, but you might lose minutes of data.
AOF (Append-Only File) - Logs every write operation. More durable, but larger files and slower startup.
You can tune Redis for:
- Maximum performance (no persistence)
- Strong durability (AOF with fsync on every write)
- Something in between (most common: AOF with fsync every second)
# In redis.conf
appendonly yes
appendfsync everysec # Balance between performance and durabilityRedis is not a primary database for critical data. But it's also not reckless with data by default. Understand the trade-offs, configure accordingly.
Pipelines and Bulk Operations
This is something that bit me early on. Network latency kills performance with Redis.
// BAD: Makes 1000 round trips (~5 seconds)
for (let i = 0; i < 1000; i++) {
await redis.set(`key:${i}`, `value:${i}`);
}
// GOOD: Batches into one round trip (~50ms)
const pipeline = redis.pipeline();
for (let i = 0; i < 1000; i++) {
pipeline.set(`key:${i}`, `value:${i}`);
}
await pipeline.exec();Even if Redis processes each command in microseconds, network round trips take milliseconds. That adds up fast. Pipelines can turn a 5-second operation into a 50ms operation.
The difference is dramatic.
When NOT to Use Redis
Let's be honest about limitations. Redis struggles when:
Complex relational queries are needed - If you need JOINs across multiple tables with complex WHERE clauses, use PostgreSQL. Don't try to recreate SQL in Redis. I've seen this attempted. It never ends well.
Data outgrows memory - Redis loads everything into RAM. If your dataset is 100GB and you have 16GB of memory, Redis isn't going to work. Period.
Absolute durability is required - While Redis has persistence, certain failure scenarios can lose data. For financial transactions or anything where data loss is catastrophic, use a database designed for that.
Full-text search and analytics - Redis has search capabilities (RediSearch module), but Elasticsearch or similar are better for complex full-text search and analytics queries.
Using Redis as a primary database for business-critical data is usually a mistake. Using it as a focused system component for the right use cases usually isn't.
The Architecture Pattern That Scales
Here's the mental model that's served me well:
Redis is shared, fast, in-memory state with atomic operations you can rely on.
It's not a dumping ground for anything slow. It's not a shortcut to avoid thinking about your data model. It's a tool that rewards careful modeling and punishes misuse.
Think about what kind of state you're managing:
- Derived state (caches, counters, aggregations) → Redis is perfect
- Shared state (sessions, locks, rate limits) → Redis is perfect
- Ordered state (queues, leaderboards, time-series) → Redis is perfect
- Location-based state (geospatial queries) → Redis is perfect
- Primary business data (user accounts, orders, inventory) → PostgreSQL/MySQL
The architecture becomes clearer when you stop treating every data store as a general-purpose hammer.
Lessons After Years in Production
Start simple - Use Redis as a cache. Get comfortable with basic operations. But keep the docs handy and stay curious about what else it can do.
Know your data structures - Spend an afternoon really understanding what each Redis data structure does best. This knowledge pays compound interest. When you're solving a problem and suddenly realize "wait, sorted sets are perfect for this," that's when Redis becomes powerful.
Monitor your memory - Memory is your limiting factor with Redis. Use redis-cli --bigkeys to find memory hogs. Set maxmemory and maxmemory-policy configurations appropriately. Watch your memory usage in production. I've been paged at 3am because someone forgot to set a TTL on cache keys. Don't be that person.
Use connection pooling - Every Redis client library has connection pooling. Use it. Opening TCP connections is expensive. Configure pool size based on your concurrency needs (we typically use 10-20 connections per app server).
Think in pipelines - If you're making multiple sequential Redis calls, batch them with pipelines. The latency savings are huge, especially if your Redis instance isn't on localhost.
Don't fight Redis's design - Redis is optimized for simple, fast operations. If you find yourself doing complex multi-key transactions or trying to implement joins, you're probably using the wrong tool.
Test failover scenarios - Redis going down shouldn't bring your whole system down. Make sure your app degrades gracefully. We learned this the hard way during a Redis outage that cascaded into a full site outage.
The Real Shift
Here's what I want you to take away:
Stop thinking of Redis as "that cache layer" and start thinking of it as a data structure server that happens to be incredibly fast.
When you're designing a system and you think "I need a queue" or "I need a leaderboard" or "I need to track active users," don't immediately jump to "build it in Postgres and cache it in Redis."
Ask yourself: "Can Redis just be the source of truth for this?"
Sometimes the answer is yes, and your architecture becomes simpler and faster as a result.
Redis won't replace your primary database for most things. But it's also way more than a cache. It's a fundamental building block for modern, high-performance systems that gets more valuable the more you understand it.
Give it a shot. Build something with sorted sets or pub/sub or geospatial indexes. I think you'll be surprised at what becomes possible when you stop treating Redis as "just" anything.
What's your experience with Redis? Are you using it beyond caching? I'd love to hear what you've built with it.